YOLOv5 object detection experiments
Marton Trencseni - Fri 02 July 2021 - Data
Introduction
YOLOv5 is a set of pre-trained PyTorch neural network based image detection and classification models. With YOLOv5, performing image detection and classification is a couple of lines of code, whether the source is a local image, an image URL, a video or a live stream, such as a laptop's webcam. For example:
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
results = model(['https://www.brianhonigman.com/wp-content/uploads/2015/10/Large-crowd-of-people-014.jpg'])
results.show()
Yields:

What's happening in the above code:
- YOLOv5s, the Small version of the YOLOv5 pre-trained neural network is downloaded from PyTorch Hub
- The image is retrieved from the URL
- Object detection is run on the image
- Image with multiple bounding boxes and confidences is shown
If we git clone the full YOLOv5 repo, we get helper scripts which make running the models on the laptop's webcam feed a one-liner:
$ git clone https://github.com/ultralytics/yolov5/
$ cd yolov5
$ python3 detect.py --source 0
Here is YOLOv5s correctly detecting me and some objects in the background, under low light conditions which make the image grainy:

Here I put my sunglasses close to my mouth, which fools the model into thinking it's toothbrush:
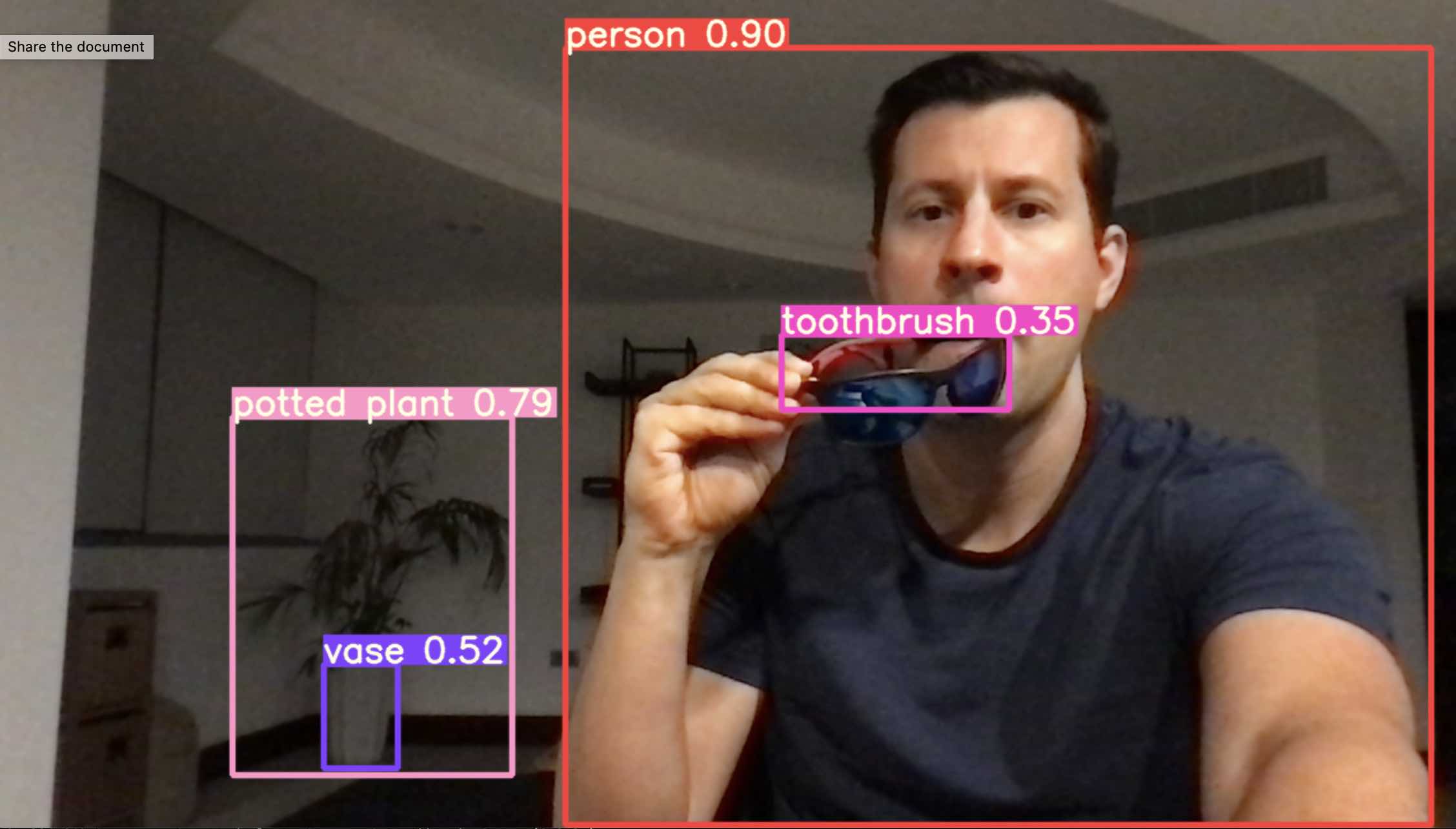
The above is running S (small) version of the network, which runs at real-time FPS. Bigger models may not be able to handle real-time depending on the hardware.
It's worth noting the difference between object classification and object detection:
- In object classification, the entire image is assigned one category. For example, with MNIST digits, each image of a hand-written digit belongs to one of 10 classes. The task is not to locate the digit on the image, just to figure out which digit (if any) is most likely on the image. See this earlier post about MNIST digit detection with Pytorch.
- Object detection is much harder. Here, the image potentially contains multiple objects, each belonging to a different class (eg. person, car, dog). The task is to locate each object (bounding box or pixels) and for each located object, return the most likely class.
Previous computer vision approaches consisted of multiple independent steps, for example in step 1 detect objects (for example using features such as edges and contours), whatever the object may be, then in step 2 classify the detected objects. The downside of these approaches is that the two sub-modules are trained independently, so errors cannot propagate from one to the other. Another possibility is to just take an image classifier, and run it repeatedly on sections of the image. This can be very slow as the model is run repeatedly at different coordinates for different window sizes, since this is essentially a brute-force approach.
YOLO stands for You Only Look Once. In the YOLO architecture, a deep neural network is trained to perform multiple object detection and classification in one go: find both the bounding boxes of objects on the image, and their probable class (eg. person, car, dog). The best reference for the YOLO architecture is the original 2015 paper. I will not discuss the details of the architecture in this post, just highlight that the YOLO, specifically YOLOv5 architecture is state-of-the-art as of the writing of this post:

YOLO is very popular, so there are many good tutorial and dicussions of the architecture. Good starting points are:
- official YOLOv5 Github repo with documentation
- original 2015 paper
- explanation on TDS
- end-to-end tutorial on TDS
- how to train your own YOLOv5 networks
There are 2 option if one wants to use YOLO:
- Download a pre-trained model.
- Train a model yourself: the Github repo contains documentation on how to. You will need a set of labeled images (bounding boxes and classification per bounding box).
I was curious about the performance of the pre-trained models. Models, because there are difference sizes of YOLOv5 models available, from S for Small to X for Xlarge, the biggest. The smallest S model runs about 7x faster than the biggest X model, but finds less objects and is less certain of the findings. Here I will show results for S and X.

Limitations
The YOLO architecture is fundamentally a deep convolutional neural network (CNN), as illustrated by this high-level diagram from the original YOLO paper:

Although being able to download a pre-trained neural network and get pretty good object detection in 3 lines of Python is machine-learning-magic, it's worth remembering that:
- The model will only detect objects it was trained to detect: for example, if the training set didn't include any turtles, then the model will never return turtles. YOLOv5 is pre-trained on the COCO dataset and knows about 80 classes.
- CNNs such as YOLOv5 are not naturally scale or rotation invariant. This has to be taught at training time, for example by scaling and rotating the training images and passing them in as separate images during training.
- There is a global maximum number of object YOLOv5 can detect, 300. There are also local maximums that it can detect, due to the architecture of the neural network. So if there is a large image, wit a smaller section containing 100s of objects to be detected, the user will run into this local maximum constraint.
Below I run experiments to understand how the pre-trained YOLOv5 models react to rotation, scaling, stretching and blurring. The ipython notebook is up on Github. Note that YOLOv5 cuts of confidence at 0.3, so if an object detection's confidence is less than 0.3, the object is not returned. This is why confidences lower than 0.3 ever occur on the plots below. For the experiments I use a picture of a yellow Porsche 911:

Rotation
First, I test object detection as a function of image rotation. I rotate the car 0, 1 ... 90 degrees using the Pillow image manipulation library, and run YOLOv5s and YOLOv5x on the modified image:
ms = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
mx = torch.hub.load('ultralytics/yolov5', 'yolov5x', pretrained=True)
for angle in range(0, 91, 1):
image_mod = image.rotate(angle)
detections = ms([image_mod]), mx([image_mod])
...
Detection confidences:
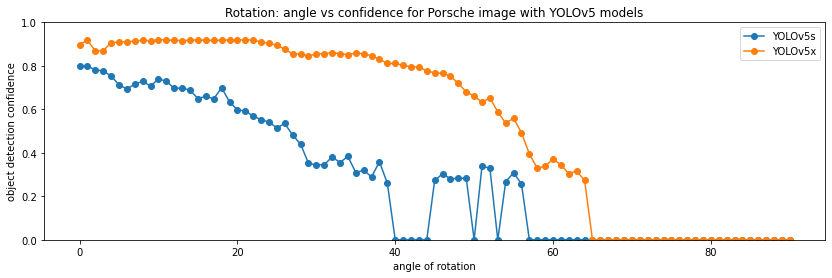
It's really interesting how at some "critical" angles the S model fails (the confidence drops below 0.3), but then at higher angles it's back up again. The X model is able to detect the car at angles up to 65 degrees.
Scaling
Next, I scale the image by 0.1, 0.2 ... 1.0, ie. I make it smaller:
for scale in np.arange(0.1, 1.1, 0.1):
image_mod = image.resize((int(width*scale), int(height*scale)), Image.ANTIALIAS)
detections = ms([image_mod]), mx([image_mod])
...
Detection confidences:
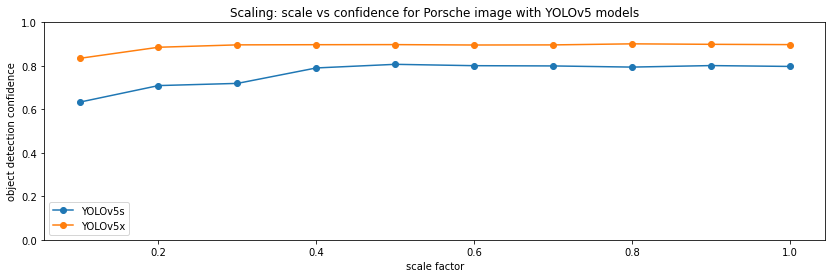
At least on this clean picture, scaling is not a problem for YOLOv5, even the smallest 0.1x image is confidently detected.
Stretching
Next, I stretch the image, first in the vertical direction, then in the horizontal direction. The code is similar to the stretching case, so I just show the results:
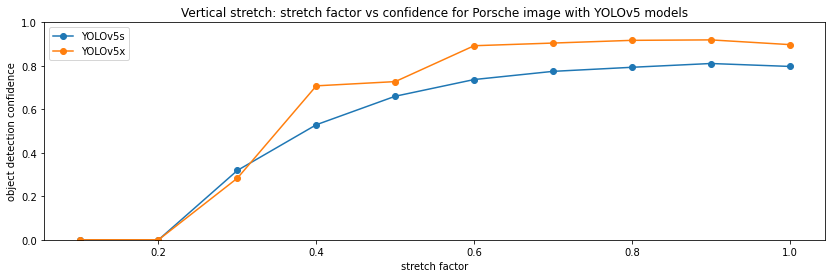
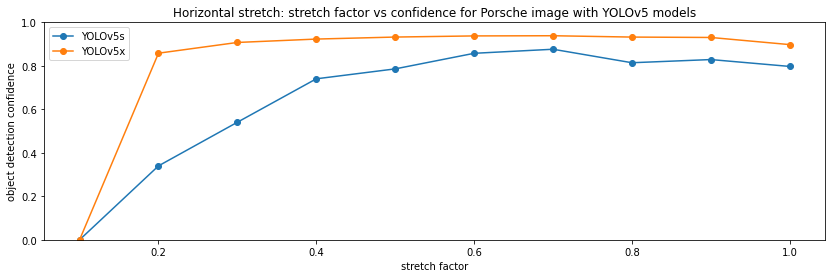
Here, YOLOv5 also performs very well. From a stretch factor of 0.2-0.3, it's able to recognize the car.
Blurring
Next, I apply a gaussian blur of increasing stregth:
for blur in range(0, 15, 1):
image_mod = image.filter(ImageFilter.GaussianBlur(blur))
detections = ms([image_mod]), mx([image_mod])
...
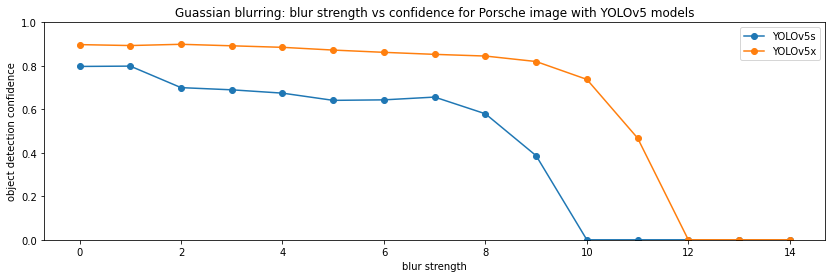
Finally, I also try blurring on the picture of crowd of people shown at the beginning of the post. Since the picture contains 50+ people, instead of plotting a single confidence, I plot the number of people detected:
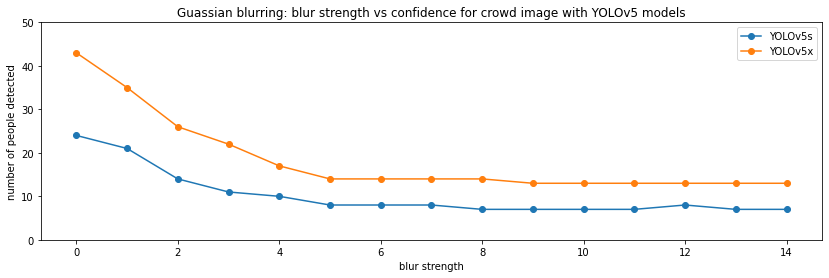
On the simple car picture, the model breaks down at a blur factor of about 10-12, whereas on the more realistic crown picture the starts to miss people much earlier, at lower blur factors.
Conclusion
In Dubai, privacy laws prohibit the storage of videos taken of people. Since we cannot store CCTV video feeds, we cannot label it and train our own (YOLOv5 or other) models on our own labeled images. Hence, using pre-trained models such as YOLOv5 is our only option. This is true irrespective of the intended usage of the model, even if it is privacy-neutral, for example count people entering and leaving through the door.
The above experiments show that YOLOv5 does have limitations, it is not magic in the sense of being equivalent to a human. But overall I find the performance of the pre-trained YOLOv5 models quite impressive.